
Cloudflare, a worldwide web safety agency that claims to guard practically 20% of the world’s net visitors, has launched what it calls an “straightforward button” for web site house owners who wish to block AI providers from accessing their content material. The transfer comes as demand for content material used to coach AI fashions has skyrocketed.
Cloudflare’s core service, which serves as an web proxy, scans and filters net visitors earlier than it reaches web sites. On common, the agency says its community sees over 57 million requests per second.
“To assist protect a protected web for content material creators, we have simply launched a model new ‘straightforward button’ to dam all AI bots,” Cloudflare stated in its announcement on Wednesday. “We hear clearly that clients don’t need AI bots visiting their web sites, and particularly people who achieve this dishonestly.”
Whereas some AI corporations correctly establish their net scraping bots and respect web site directions to remain away, not all of them are clear about their actions.
The brand new easy setting is being made obtainable to all Cloudflare clients, together with these on its free tier.
Dissecting AI bot exercise
Together with its announcement, Cloudflare shared a plethora of details about the AI crawler exercise it observes throughout its methods.
In keeping with Cloudflare’s knowledge, AI bots accessed round 39% of the highest a million “web properties” utilizing Cloudflare in June. Nonetheless, solely 2.98% of those properties took measures to dam or problem these requests. Cloudflare additionally mentions that “the higher-ranked (extra standard) an web property is, the extra doubtless it’s to be focused by AI bots.”
The agency stated net crawlers operated by TikTok proprietor ByteDance, Amazon, Anthropic, and OpenAI have been essentially the most energetic. The highest crawler was Bytedance’s Bytespider, which topped the charts in variety of requests, the scope of its exercise, and the frequency of being blocked. GPTBot, managed by OpenAI and used to gather coaching knowledge for merchandise like ChatGPT, ranked second in each crawling exercise and blocks.
The net crawler for Perplexity, which has just lately drawn controversy for its content material crawling practices, was detected visiting a fraction of a % of the websites Cloudflare protects.
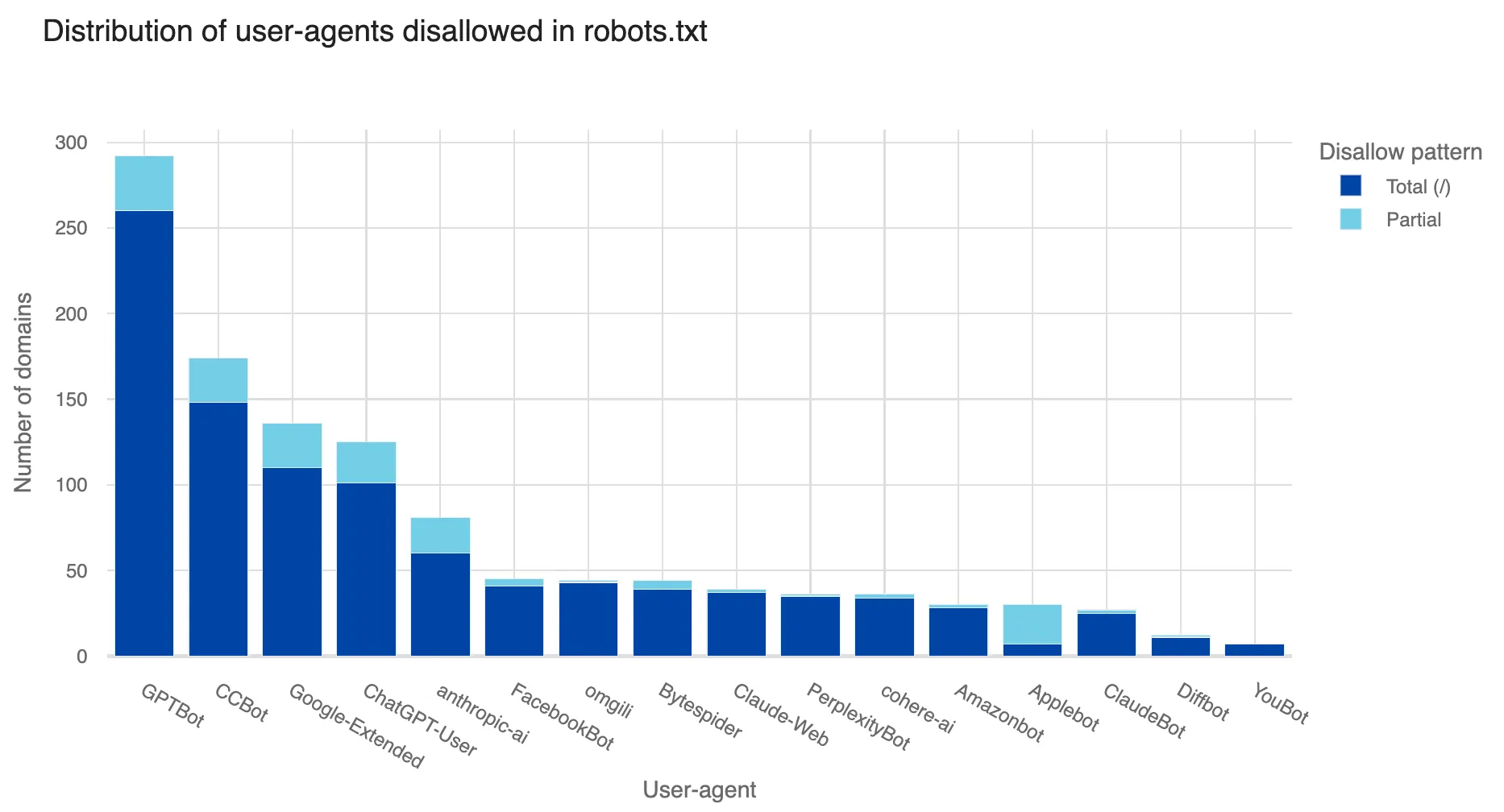
Whereas web site house owners can implement their very own guidelines to dam identified net crawlers, Cloudflare additionally stated that almost all of its shoppers that achieve this are solely blocking extra mainstream AI builders like OpenAI, Google, or Meta, however not the highest crawler from Bytedance or different corporations.
AI versus AI
Cloudflare’s report highlighted how some AI bot operators are resorting to misleading techniques to sidestep measures to dam them, trying to go off their crawler exercise as authentic net visitors.
“Sadly, we have noticed bot operators try to look as if they’re an actual browser through the use of a spoofed consumer agent,” Cloudflare wrote.
Because it seems, AI is a key device within the firm’s arsenal to cease automated exercise—whether or not from AI builders, search engines like google and yahoo, or malicious attackers. Cloudflare stated it makes use of a machine studying mannequin to assign a “bot rating” to every request made to a web site protected by its providers, with low scores indicating a low probability that the exercise is authentic.
With Cloudflare’s large dataset on international web visitors, the mannequin takes into consideration a variety of indicators, together with the request’s IP handle, consumer agent, and habits patterns, to find out the bot rating.
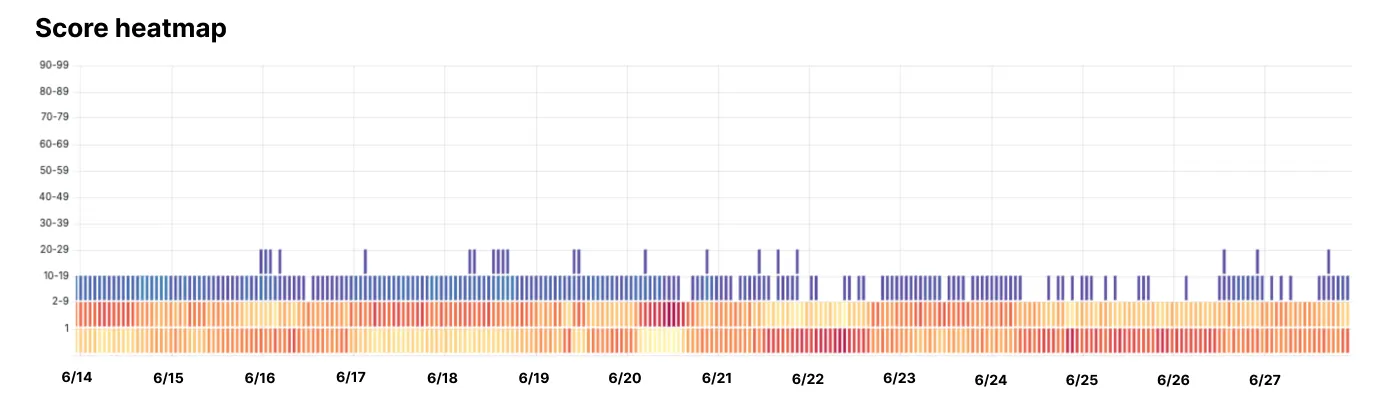
For instance this, Cloudflare stated it checked out visitors from a selected bot identified for its evasive habits. The outcomes have been telling: all detections have been scored under 30 out of 100, with the overwhelming majority falling into the underside two bands, indicating a rating of 9 or much less. In different phrases, even with makes an attempt to obscure its supply, the bot’s exercise patterns gave it away—permitting Cloudflare to dam it.
Defending net content material
Generative AI fashions depend on titanic volumes of present content material, a lot of it collected from throughout the online. To ensure that AI to proceed to supply present info, its builders have to proceed to gather info on a big scale.
Web site house owners and content material creators are pushing again, with giant publishers like information organizations taking authorized motion towards AI corporations. Within the aforementioned case of Perplexity, publications like Forbes and Wired declare it’s taking and republishing content material with out permission. Music writer Sony preemptively warned over 700 tech companies to remain away in Might, and this week, Warner Music Group has finished the identical.
The menace might be an existential one for publishers, ought to AI more and more present info to customers with out referring them to the supply. A current examine printed by SparkToro’s CEO Rand Fishkin steered that 60% of individuals looking for info on Google stopped visiting the web sites providing it as a result of Google’s AI supplied summarized solutions instantly.
Edited by Ryan Ozawa.
Typically Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.








{kind=link}