
The AI artwork scene is getting hotter. Sana, a brand new AI mannequin launched by Nvidia, runs high-quality 4K picture technology on consumer-grade {hardware}, due to a intelligent mixture of methods that differ a bit from the way in which conventional picture turbines work.
Sana’s pace comes from what Nvidia calls a “deep compression autoencoder” that squeezes picture knowledge all the way down to 1/thirty second of its authentic dimension—whereas preserving all the main points intact. The mannequin pairs this with the Gemma 2 LLM to grasp prompts, making a system that punches effectively above its weight class on modest {hardware}.
If the ultimate product is pretty much as good as the general public demo, Sana guarantees to be a model new picture generator constructed to run on much less demanding methods, which will likely be an enormous benefit for Nvidia because it tries to succeed in much more customers.
“Sana-0.6B may be very aggressive with fashionable big diffusion mannequin (e.g. Flux-12B), being 20 occasions smaller and 100+ occasions quicker in measured throughput,” the workforce at Nvidia wrote on Sana’s analysis paper, “Furthermore, Sana-0.6B will be deployed on a 16GB laptop computer GPU, taking lower than 1 second to generate a 1024×1024 decision picture.”
Sure, you learn that proper: Sana is a 0.6 Billion parameter mannequin that competes in opposition to fashions 20 occasions its dimension, whereas producing photos 4 occasions bigger, in a fraction of the time. If that sounds too good to be true, you may attempt it your self on a particular interface arrange by the MIT.
Nvidia’s timing could not be extra pointed, with fashions just like the just lately launched Secure Diffusion 3.5, the beloved Flux, and the brand new Auraflow already battling for consideration. Nvidia plans to launch its code as open supply quickly, a transfer that would solidify its place within the AI artwork world—whereas boosting gross sales of its GPUs and software program instruments, we could add.
The Holy Trinity that make Sana so good
Sana is mainly a reimagination of the way in which conventional picture turbines work. However there are three key parts that make this mannequin so environment friendly.
First, is Sana’s deep compression autoencoder, which shrinks picture knowledge to a mere 3% of its authentic dimension. The researchers say, this compression makes use of a specialised method that maintains intricate particulars whereas dramatically decreasing the processing energy wanted.
You may consider this as an optimized substitute to the Variable Auto Encoder that’s applied in Flux or Secure Diffusion. The encode/decode course of in Sana is constructed to be quicker and extra environment friendly.
These auto encoders mainly translate the latent representations (what the AI understands and generates) into photos.
Secondly, Nvidia overhauled the way in which its mannequin offers with prompts—which is by encoding and decoding textual content. Most AI artwork instruments use textual content encoders like T5 or CLIP to mainly translate the person’s immediate into one thing an AI can perceive—latent representations from textual content. However Nvidia selected to make use of Google’s Gemma 2 LLM.
This mannequin does mainly the identical factor, however stays mild whereas nonetheless catching nuances in person prompts. Sort in “sundown over misty mountains with historical ruins,” and it will get the image—actually—with out maxing out your laptop’s reminiscence.
However the Linear Diffusion Transformer might be the primary departure from conventional fashions. Whereas different AI instruments use complicated mathematical operations that bathroom down processing, Sana’s LDT strips away pointless calculations. The consequence? Lightning-fast picture technology with out high quality loss. Consider it as discovering a shortcut by means of a maze—identical vacation spot, however a a lot quicker route.
This may very well be an alternative choice to the UNet structure that AI artists know from fashions like Flux or Secure Diffusion. The UNet is what transforms noise (one thing that is unnecessary) into a transparent picture by making use of noise-removal methods, steadily refining the picture by means of a number of steps—essentially the most resource-hungry course of in picture turbines.
So, the LDT in Sana primarily performs the identical “de-noising” and transformation duties because the UNet in Secure Diffusion however with a extra streamlined method. This makes LDT an important think about attaining excessive effectivity and pace in Sana’s picture technology, whereas UNet stays central to Secure Diffusion’s performance, albeit with increased computational calls for.
Primary Assessments
Because the mannequin isn’t publicly launched, we received’t share an in depth evaluation. However a few of the outcomes we obtained from the mannequin’s demo website had been fairly good.
Sana proved to be fairly quick. For comparability, it was capable of generate 4K photos, rendering 30 steps in lower than 10 seconds. That’s even quicker than the time it takes Flux Schnell to generate an analogous picture in 4 steps with 1080p sizes.
Listed here are some outcomes, utilizing the identical prompts we used to benchmark different picture turbines:
Immediate 1: “Hand-drawn illustration of an enormous spider chasing a girl within the jungle, extraordinarily scary, anguish, darkish and creepy surroundings, horror, hints of analog images affect, sketch.”


Immediate 2: A black and white photograph of a girl with lengthy straight hair, sporting an all-black outfit that accentuates her curves, sitting on the ground in entrance of a contemporary couch. She is posing confidently for the digicam, showcasing her slender legs as she crouches down. The background incorporates a minimalist design, emphasizing her elegant pose in opposition to the stark distinction between mild grey partitions and darkish apparel. Her expression exudes confidence and class. Shot by Peter Lindbergh utilizing Hasselblad X2D 105mm lens at f/4 aperture setting. ISO 63. Skilled coloration grading enhances the visible enchantment.


Immediate 3: A Lizard Carrying a Swimsuit


Immediate 4: An attractive girl mendacity on grass


Immediate 5: “A canine standing on prime of a TV displaying the phrase ‘Decrypt’ on the display screen. On the left there’s a girl in a enterprise go well with holding a coin, on the fitting there’s a robotic standing on prime of a primary support field. The general surroundings is surreal.”


The mannequin can be uncensored, with a correct understanding of each female and male anatomy. It can additionally make it simpler to advantageous tune as soon as it’s launched. However contemplating the essential quantity of architectural adjustments, it stays to be seen how a lot of a problem will probably be for mannequin builders to grasp its intricacies and launch customized variations of Sana.
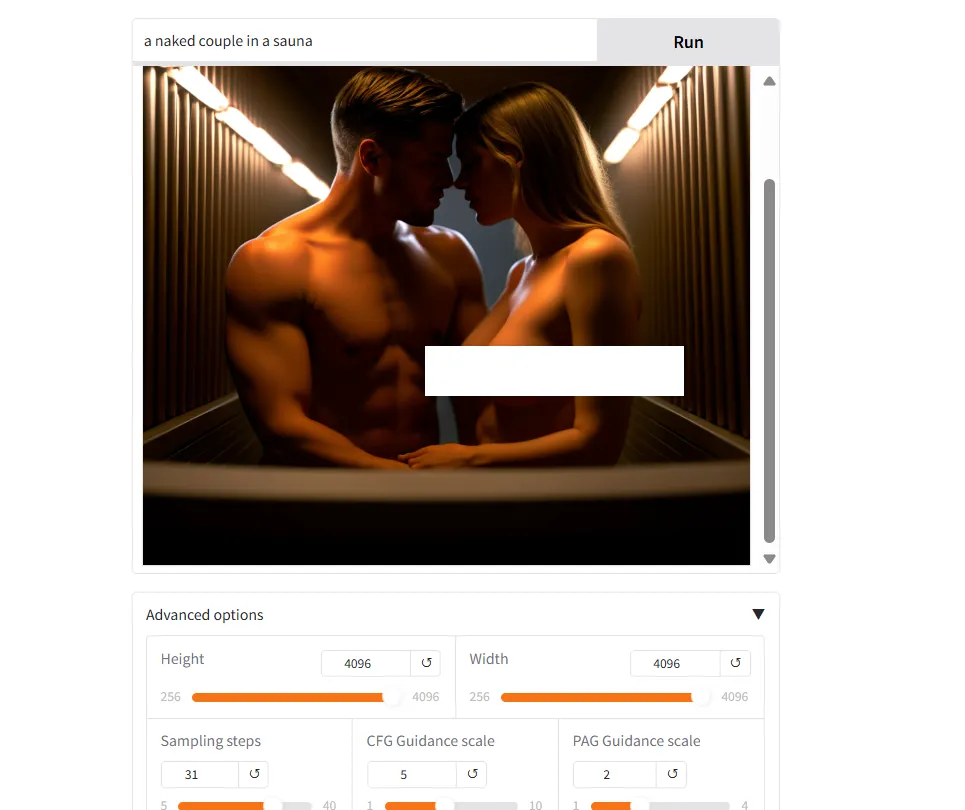
Primarily based on these early outcomes, the bottom mannequin, nonetheless in preview, appears good with realism whereas bein versatile sufficient for different sorts of artwork. It’s good by way of house consciousness however its major flaw is its lack of correct textual content technology and lack of element underneath some situations.
The pace claims are fairly spectacular, and the flexibility to generate 4096×4096—which is technically increased than 4k—is one thing outstanding, contemplating that such sizes can solely be correctly achieved at the moment with upscaling methods.
The truth that will probably be open supply can be a serious constructive, so we might quickly be reviewing fashions and finetunes able to producing extremely excessive definition photos with out placing an excessive amount of stress on client {hardware}.
Sana’s weights will likely be launched on the venture’s official Github.
Usually Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.








{kind=link}