Chinese language AI researchers have achieved what many thought was gentle years away: A free, open-source AI mannequin that may match or exceed the efficiency of OpenAI’s most superior reasoning methods. What makes this much more exceptional was how they did it: by letting the AI train itself by way of trial and error, much like how people be taught.
“DeepSeek-R1-Zero, a mannequin skilled by way of large-scale reinforcement studying (RL) with out supervised fine-tuning (SFT) as a preliminary step, demonstrates exceptional reasoning capabilities.” the analysis paper reads.
“Reinforcement studying” is a technique through which a mannequin is rewarded for making good selections and punished for making unhealthy ones, with out understanding which one is which. After a collection of choices, it learns to observe a path that was bolstered by these outcomes.
Initially, throughout the supervised fine-tuning part, a gaggle of people tells the mannequin the specified output they need, giving it context to know what’s good and what isn’t. This results in the following part, Reinforcement Studying, through which a mannequin gives completely different outputs and people rank one of the best ones. The method is repeated time and again till the mannequin is aware of constantly present passable outcomes.
Picture: Deepseek
DeepSeek R1 is a steer in AI improvement as a result of people have a minimal half within the coaching. In contrast to different fashions which might be skilled on huge quantities of supervised knowledge, DeepSeek R1 learns primarily by way of mechanical reinforcement studying—basically figuring issues out by experimenting and getting suggestions on what works.
“By way of RL, DeepSeek-R1-Zero naturally emerges with quite a few highly effective and fascinating reasoning behaviors,” the researchers stated of their paper. The mannequin even developed subtle capabilities like self-verification and reflection with out being explicitly programmed to take action.
Because the mannequin went by way of its coaching course of, it naturally realized to allocate extra “considering time” to advanced issues and developed the power to catch its personal errors. The researchers highlighted an “a-ha second” the place the mannequin realized to reevaluate its preliminary approaches to issues—one thing it wasn’t explicitly programmed to do.
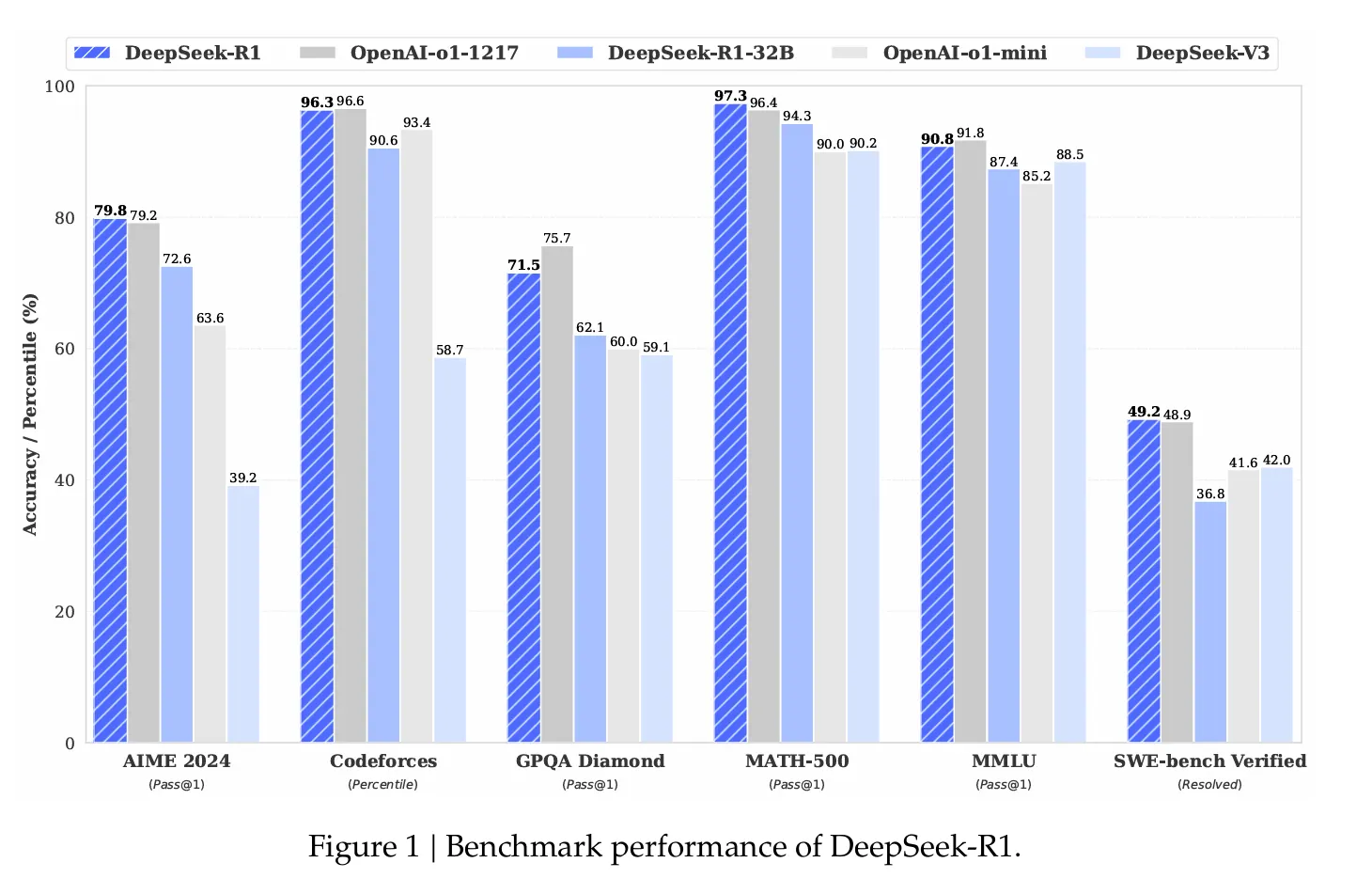
The efficiency numbers are spectacular. On the AIME 2024 arithmetic benchmark, DeepSeek R1 achieved a 79.8% success charge, surpassing OpenAI’s o1 reasoning mannequin. On standardized coding checks, it demonstrated “professional stage” efficiency, attaining a 2,029 Elo ranking on Codeforces and outperforming 96.3% of human opponents.
Picture: Deepseek
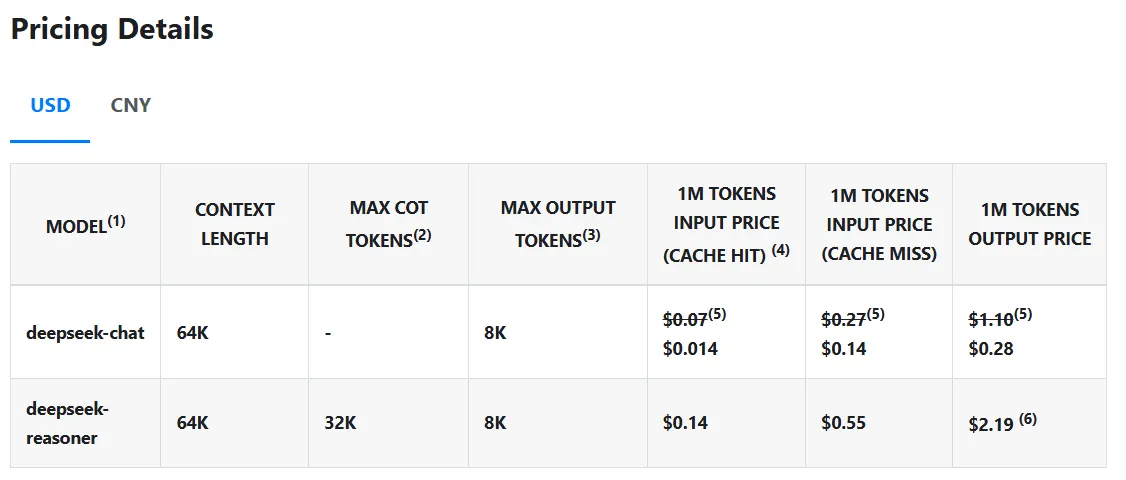
However what actually units DeepSeek R1 aside is its value—or lack thereof. The mannequin runs queries at simply $0.14 per million tokens in comparison with OpenAI’s $7.50, making it 98% cheaper. And in contrast to proprietary fashions, DeepSeek R1’s code and coaching strategies are utterly open supply underneath the MIT license, which means anybody can seize the mannequin, use it and modify it with out restrictions.
Picture: Deepseek
AI leaders react
The discharge of DeepSeek R1 has triggered an avalanche of responses from AI trade leaders, with many highlighting the importance of a completely open-source mannequin matching proprietary leaders in reasoning capabilities.
Nvidia’s prime researcher Dr. Jim Fan delivered maybe probably the most pointed commentary, drawing a direct parallel to OpenAI’s authentic mission. “We live in a timeline the place a non-U.S. firm is retaining the unique mission of OpenAI alive—actually open frontier analysis that empowers all,” Fan famous, praising DeepSeek’s unprecedented transparency.
We live in a timeline the place a non-US firm is retaining the unique mission of OpenAI alive – actually open, frontier analysis that empowers all. It is not sensible. Probably the most entertaining consequence is the most definitely.
DeepSeek-R1 not solely open-sources a barrage of fashions however… pic.twitter.com/M7eZnEmCOY
— Jim Fan (@DrJimFan) January 20, 2025
Fan known as out the importance of DeepSeek’s reinforcement studying strategy: “They’re maybe the primary [open source software] mission that exhibits main sustained development of [a reinforcement learning] flywheel. He additionally lauded DeepSeek’s easy sharing of “uncooked algorithms and matplotlib studying curves” versus the hype-driven bulletins extra widespread within the trade.
Apple researcher Awni Hannun talked about that folks can run a quantized model of the mannequin regionally on their Macs.
DeepSeek R1 671B working on 2 M2 Ultras quicker than studying pace.
Getting near open-source O1, at dwelling, on shopper {hardware}.
With mlx.distributed and mlx-lm, 3-bit quantization (~4 bpw) pic.twitter.com/RnkYxwZG3c
— Awni Hannun (@awnihannun) January 20, 2025
Historically, Apple units have been weak at AI on account of their lack of compatibility with Nvidia’s CUDA software program, however that seems to be altering. For instance, AI researcher Alex Cheema was able to working the total mannequin after harnessing the facility of 8 Apple Mac Mini models working collectively—which continues to be cheaper than the servers required to run probably the most highly effective AI fashions presently accessible.
That stated, customers can run lighter variations of DeepSeek R1 on their Macs with good ranges of accuracy and effectivity.
Nonetheless, probably the most fascinating reactions got here after pondering how shut the open supply trade is to the proprietary fashions, and the potential affect this improvement might have for OpenAI because the chief within the area of reasoning AI fashions.
Stability AI’s founder Emad Mostaque took a provocative stance, suggesting the discharge places stress on better-funded opponents: “Are you able to think about being a frontier lab that is raised like a billion {dollars} and now you’ll be able to’t launch your newest mannequin as a result of it could actually’t beat DeepSeek?”
Are you able to think about being a “frontier” lab that is raised like a billion {dollars} and now you’ll be able to’t launch your newest mannequin as a result of it could actually’t beat deepseek? 🐳
Sota generally is a bitch if thats your goal
— Emad (@EMostaque) January 20, 2025
Following the identical reasoning however with a extra severe argumentation, tech entrepreneur Arnaud Bertrand defined that the emergence of a aggressive open supply mannequin could also be probably dangerous to OpenAI, since that makes its fashions much less enticing to energy customers who may in any other case be keen to spend some huge cash per process.
“It is basically as if somebody had launched a cellular on par with the iPhone, however was promoting it for $30 as an alternative of $1000. It is this dramatic.”
Most individuals in all probability do not realize how unhealthy information China’s Deepseek is for OpenAI.
They’ve provide you with a mannequin that matches and even exceeds OpenAI’s newest mannequin o1 on varied benchmarks, they usually’re charging simply 3% of the value.
It is basically as if somebody had launched a… pic.twitter.com/aGSS5woawF
— Arnaud Bertrand (@RnaudBertrand) January 21, 2025
Perplexity AI’s CEO Arvind Srinivas framed the discharge by way of its market affect: “DeepSeek has largely replicated o1 mini and has open-sourced it.” In a follow-up remark, he famous the speedy tempo of progress: “It is type of wild to see reasoning get commoditized this quick.”
It is kinda wild to see reasoning get commoditized this quick. We should always totally count on an o3 stage mannequin that is open-sourced by the top of the yr, in all probability even mid-year. pic.twitter.com/oyIXkS4uDM
— Aravind Srinivas (@AravSrinivas) January 20, 2025
Srinivas stated his staff will work to deliver DeepSeek R1’s reasoning capabilities to Perplexity Professional sooner or later.
Fast hands-on
We did just a few fast checks to match the mannequin in opposition to OpenAI o1, beginning with a widely known query for these sorts of benchmarks: “What number of Rs are within the phrase Strawberry?”
Sometimes, fashions wrestle to supply the proper reply as a result of they don’t work with phrases—they work with tokens, digital representations of ideas.
GPT-4o failed, OpenAI o1 succeeded—and so did DeepSeek R1.
Nonetheless, o1 was very concise within the reasoning course of, whereas DeepSeek utilized a heavy reasoning output. Apparently sufficient, DeepSeek’s reply felt extra human. Through the reasoning course of, the mannequin appeared to speak to itself, utilizing slang and phrases which might be unusual on machines however extra extensively utilized by people.
For instance, whereas reflecting on the variety of Rs, the mannequin stated to itself, “Okay, let me determine (this) out.” It additionally used “Hmmm,” whereas debating, and even stated issues like “Wait, no. Wait, let’s break it down.”
The mannequin finally reached the proper outcomes, however spent a whole lot of time reasoning and spitting tokens. Below typical pricing circumstances, this may be an obstacle; however given the present state of issues, it could actually output far more tokens than OpenAI o1 and nonetheless be aggressive.
One other check to see how good the fashions had been at reasoning was to play “spies” and establish the perpetrators in a brief story. We select a pattern from the BIG-bench dataset on Github. (The complete story is offered right here and includes a faculty journey to a distant, snowy location, the place college students and lecturers face a collection of unusual disappearances and the mannequin should discover out who was the stalker.)
Each fashions considered it for over one minute. Nonetheless, ChatGPT crashed earlier than fixing the thriller:
However DeepSeek gave the proper reply after “considering” about it for 106 seconds. The thought course of was right, and the mannequin was even able to correcting itself after arriving at incorrect (however nonetheless logical sufficient) conclusions.
The accessibility of smaller variations significantly impressed researchers. For context, a 1.5B mannequin is so small, you would theoretically run it regionally on a robust smartphone. And even a quantized model of Deepseek R1 that small was in a position to stand face-to-face in opposition to GPT-4o and Claude 3.5 Sonnet, based on Hugging Face’s knowledge scientist Vaibhav Srivastav.
“DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks with 28.9% on AIME and 83.9% on MATH.”
1.5B did WHAT? pic.twitter.com/Pk6fOJNma2
— Vaibhav (VB) Srivastav (@reach_vb) January 20, 2025
Only a week in the past, UC Berkeley’s SkyNove launched Sky T1, a reasoning mannequin additionally able to competing in opposition to OpenAI o1 preview.
These fascinated about working the mannequin regionally can obtain it from Github or Huggingf Face. Customers can obtain it, run it, take away the censorship, or adapt it to completely different areas of experience by fine-tuning it.
Or if you wish to attempt the mannequin on-line, go to Hugging Chat or DeepSeek’s Net Portal, which is an effective various to ChatGPT—particularly because it’s free, open supply, and the one AI chatbot interface with a mannequin constructed for reasoning apart from ChatGPT.
Edited by Andrew Hayward
Typically Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.













{kind=link}