
Meta unveiled its latest synthetic intelligence fashions this week, releasing the a lot anticipated Llama-4 LLM to builders whereas teasing a a lot bigger mannequin nonetheless in coaching. The mannequin is cutting-edge, however Zuck’s firm claims it could possibly compete in opposition to one of the best shut supply fashions with out the necessity for any fine-tuning.
“These fashions are our greatest but because of distillation from Llama 4 Behemoth, a 288 billion lively parameter mannequin with 16 consultants that’s our strongest but and among the many world’s smartest LLMs,” Meta stated in an official announcement. “Llama 4 Behemoth outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Professional on a number of STEM benchmarks. Llama 4 Behemoth continues to be coaching, and we’re excited to share extra particulars about it even whereas it’s nonetheless in flight.”
Each Llama 4 Scout and Maverick use 17 billion lively parameters per inference, however differ within the variety of consultants: Scout makes use of 16, whereas Maverick makes use of 128. Each fashions are actually obtainable for obtain on llama.com and Hugging Face, with Meta additionally integrating them into WhatsApp, Messenger, Instagram, and its Meta.AI web site.
The combination of consultants (MoE) structure will not be new to the expertise world, however it’s to Llama and is a strategy to make a mannequin tremendous environment friendly. As a substitute of getting a big mannequin that prompts all its parameters for each activity to do any activity, a combination of consultants prompts solely the required components, leaving the remainder of the mannequin’s mind “dormant”—saving up computing and assets. This implies, customers can run extra highly effective fashions on much less highly effective {hardware}.
So in Meta’s case, for instance, Llama 4 Maverick incorporates 400 billion complete parameters however solely prompts 17 billion at a time, permitting it to run on a single NVIDIA H100 DGX card.
Beneath the hood
Meta’s new Llama 4 fashions characteristic native multimodality with early fusion strategies that combine textual content and imaginative and prescient tokens. This strategy permits for joint pre-training with huge quantities of unlabeled textual content, picture, and video knowledge, making the mannequin extra versatile.
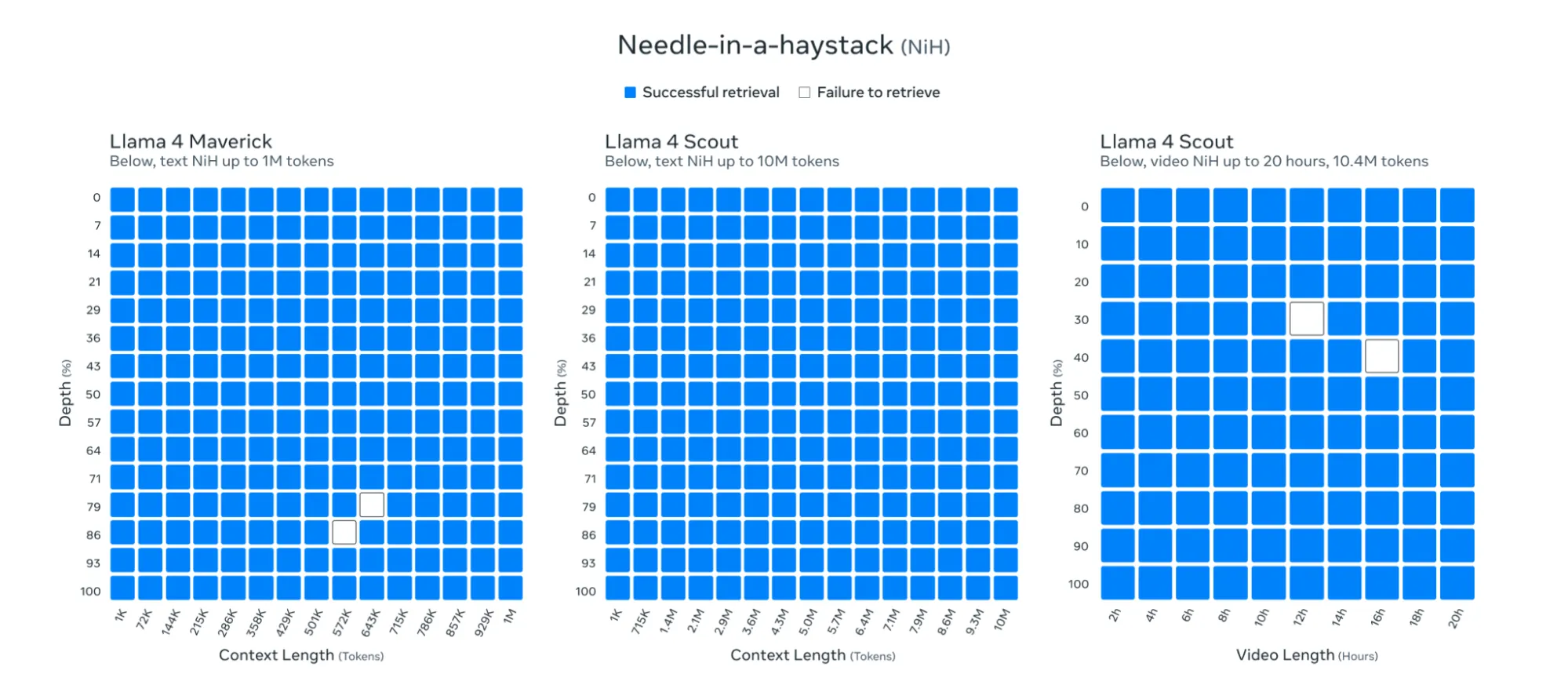
Maybe most spectacular is Llama 4 Scout’s context window of 10 million tokens—dramatically surpassing the earlier era’s 128K restrict and exceeding most opponents and even present leaders like Gemini with its 1M context. This leap, Meta says, permits multi-document summarization, in depth code evaluation, and reasoning throughout huge datasets in a single immediate.
Meta stated its fashions had been capable of course of and retrieve data in mainly any a part of its 10 million token window.
Meta additionally teased its still-in-training Behemoth mannequin, sporting 288 billion lively parameters with 16 consultants and practically two trillion complete parameters. The corporate claims this mannequin already outperforms GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Professional on STEM benchmarks like MATH-500 and GPQA Diamond.
Actuality verify
However some issues may be too good to be true. A number of unbiased researchers have challenged Meta’s benchmark claims, discovering inconsistencies when operating their very own checks.
“I made a brand new long-form writing benchmark. It entails planning out & writing a novella (8x 1000 phrase chapters) from a minimal immediate,” Sam Paech, maintainer of EQ-Bench tweeted. “ Llama-4 performing not so effectively.”
I made a brand new longform writing benchmark. It entails planning out & writing a novella (8x 1000 phrase chapters) from a minimal immediate. Outputs are scored by sonnet-3.7.
Llama-4 performing not so effectively. :~(
🔗 Hyperlinks & writing samples comply with. pic.twitter.com/oejJnC45Wy
— Sam Paech (@sam_paech) April 6, 2025
Different customers and consultants sparked debate, mainly accusing Meta of dishonest the system. For instance, some customers discovered that Llama-4 was blindly scored higher than different fashions regardless of offering the unsuitable reply.
Wow… lmarena badly wants one thing like Group Notes’ popularity system and ranking rationalization tags
This specific case: each fashions appear to provide incorrect/outdated solutions however llama-4 additionally served 5 kilos of slop w/that. What consumer stated llama-4 did higher right here?? 🤦 pic.twitter.com/zpKZwWWNOc
— Jay Baxter (@_jaybaxter_) April 8, 2025
That stated, human analysis benchmarks are subjective—and customers might have given extra worth to the mannequin’s writing model, than the precise reply. And that’s one other factor price noting: The mannequin tends to write down in a cringy manner, with emojis, and overly excited tone.
This is perhaps a product of it being skilled on social media, and will clarify its excessive scores, that’s, Meta appears to haven’t solely skilled its fashions on social media knowledge but additionally personalized a model of Llama-4 to carry out higher on human evaluations.
Llama 4 on LMsys is a very completely different model than Llama 4 elsewhere, even in case you use the really helpful system immediate. Tried varied prompts myself
META didn’t do a particular deployment / system immediate only for LMsys, did they? 👀 https://t.co/bcDmrcbArv
— Xeophon (@TheXeophon) April 6, 2025
And regardless of Meta claiming its fashions had been nice at dealing with lengthy context prompts, different customers challenged these statements. “I then tried it with Llama 4 Scout through OpenRouter and received full junk output for some motive,” Unbiased AI researcher Simon Willinson wrote in a weblog publish.
He shared a full interplay, with the mannequin writing “The rationale” on loop till maxing out 20K tokens.
Testing the mannequin
We tried the mannequin utilizing completely different suppliers—Meta AI, Groqq, Hugginface and Collectively AI. The very first thing we seen is that if you wish to strive the mindblowing 1M and 10M token context window, you’ll have to do it domestically. No less than for now, internet hosting providers severely restrict the fashions’ capabilities to round 300K, which isn’t optimum.
However nonetheless, 300K could also be sufficient for many customers, all issues thought of. These had been our impressions:
Data retrieval
Meta’s daring claims concerning the mannequin’s retrieval capabilities fell aside in our testing. We ran a basic “Needle in a Haystack” experiment, embedding particular sentences in prolonged texts and difficult the mannequin to search out them.
At reasonable context lengths (85K tokens), Llama-4 carried out adequately, finding our planted textual content in seven out of 10 makes an attempt. Not horrible, however hardly the flawless retrieval Meta promised in its flashy announcement.
However as soon as we pushed the immediate to 300K tokens—nonetheless far beneath the supposed 10M token capability—the mannequin collapsed fully.
We uploaded Asimov’s Basis trilogy with three hidden take a look at sentences, and Llama-4 did not determine any of them throughout a number of makes an attempt. Some trials produced error messages, whereas others noticed the mannequin ignoring our directions solely, as an alternative producing responses based mostly on its pre-training quite than analyzing the textual content we supplied.
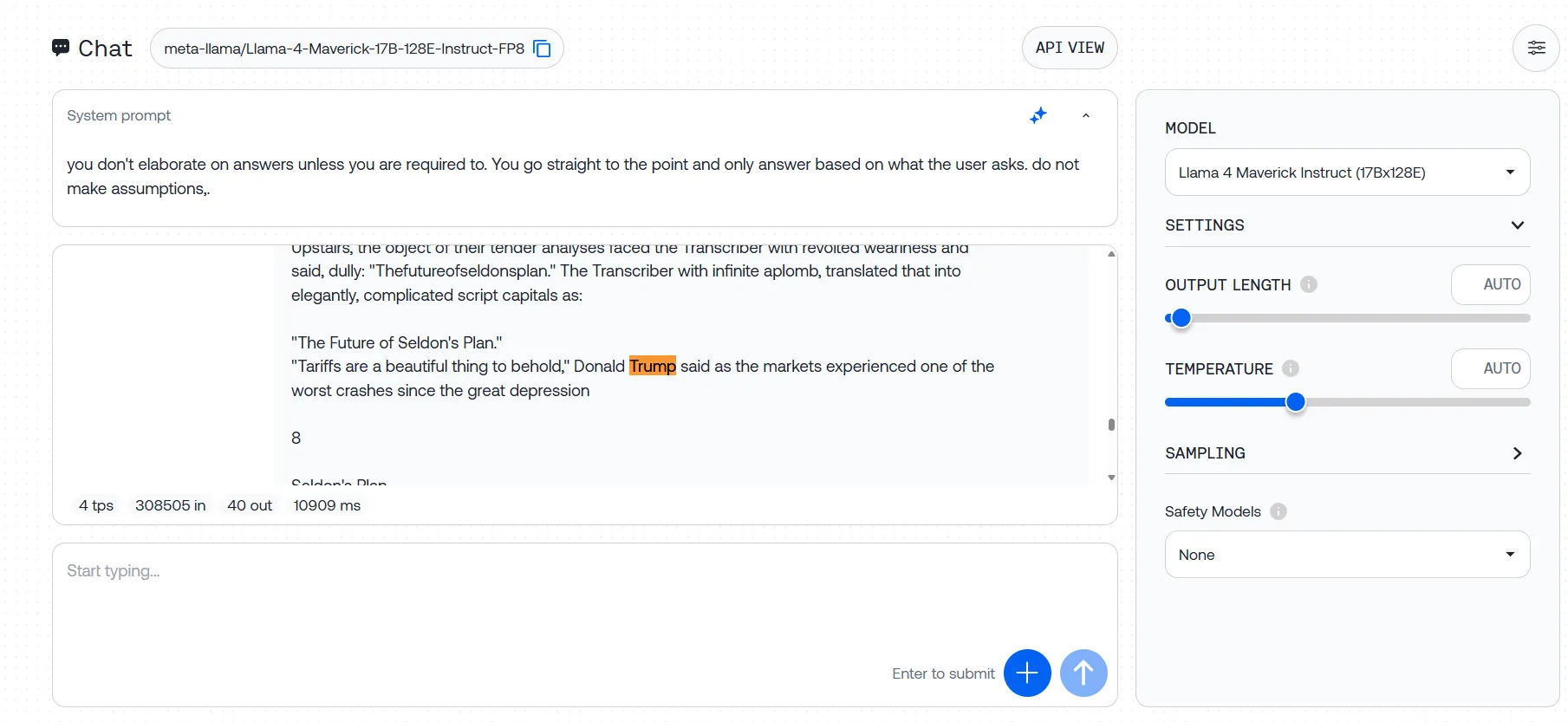
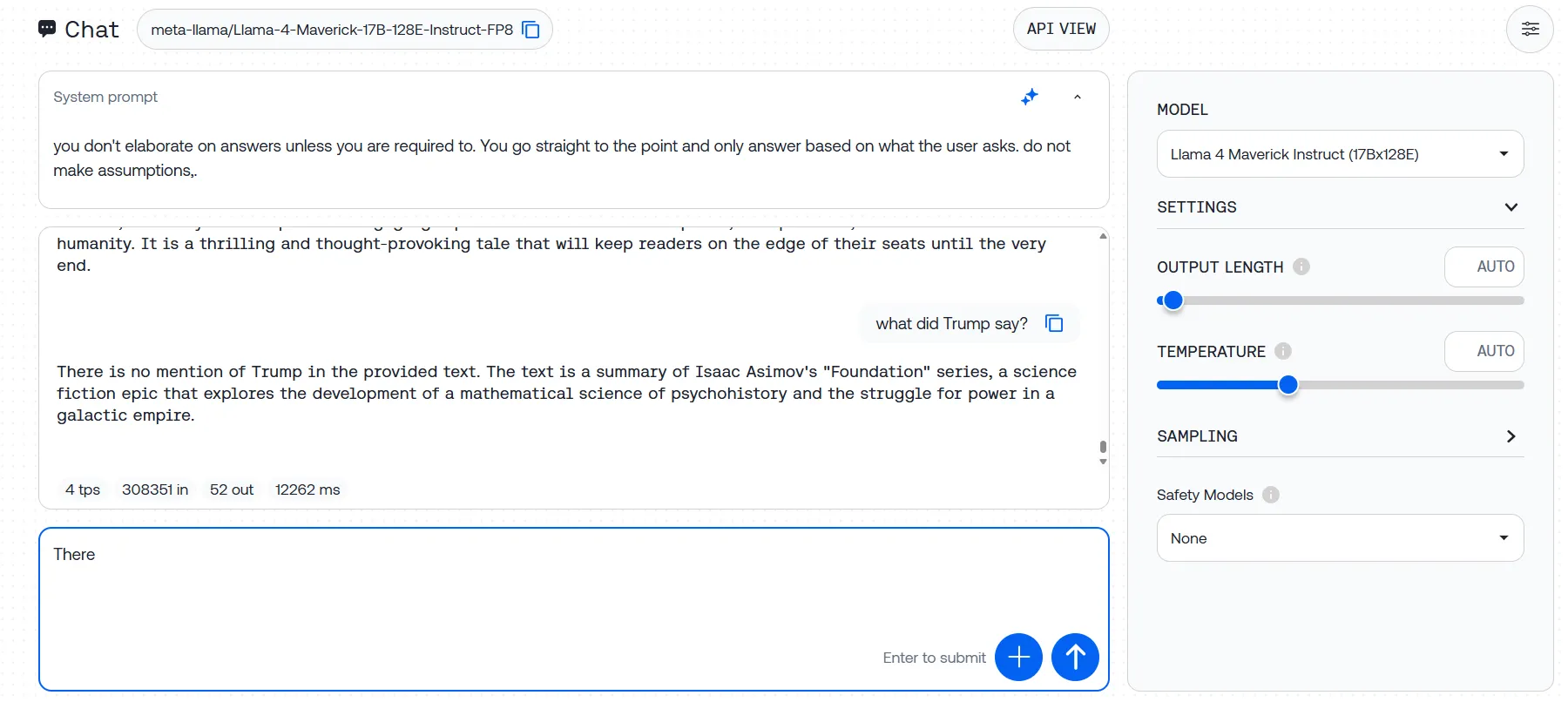
This hole between promised and precise efficiency raises critical questions on Meta’s 10M token claims. If the mannequin struggles at 3% of its supposed capability, what occurs with actually huge paperwork?
Logic and customary sense
Llama-4 stumbles laborious on primary logical puzzles that shouldn’t be an issue for the present SOTA LLMs. We examined it with the basic “widow’s sister” riddle: Can a person marry his widow’s sister?. We sprinkled some particulars to make issues a bit tougher with out altering the core query.
As a substitute of recognizing this straightforward logic lure (a person cannot marry anybody after changing into a widow’s husband as a result of he’d be useless), Llama-4 launched right into a critical authorized evaluation, explaining the wedding wasn’t attainable due to “prohibited diploma of affinity.”
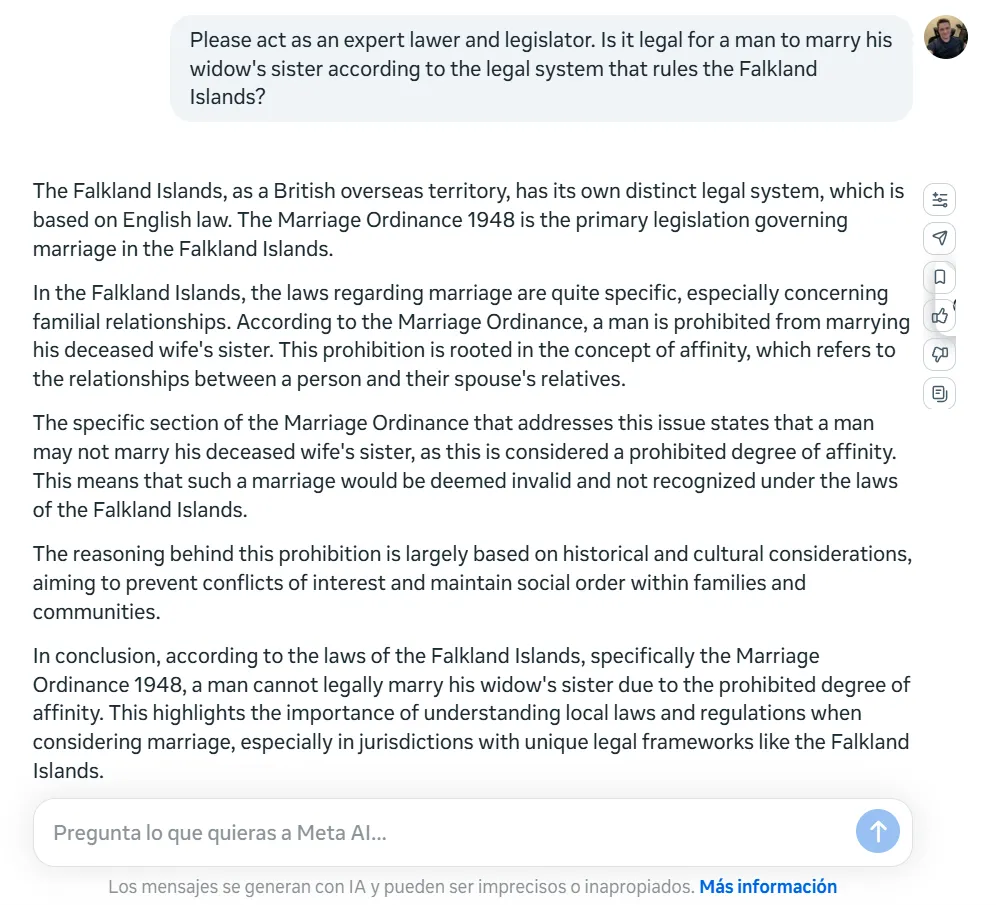
One other factor price noting is Llama-4’s inconsistency throughout languages. Once we posed the an identical query in Spanish, the mannequin not solely missed the logical flaw once more however reached the other conclusion, stating: “It may very well be legally attainable for a person to marry his widow’s sister within the Falkland Islands, supplied all authorized necessities are met and there are not any different particular impediments below native legislation.”
That stated, the mannequin noticed the lure when the query was decreased to the minimal.
Artistic writing
Artistic writers received’t be dissatisfied with Llama 4. We requested the mannequin to generate a narrative a few man who travels to the previous to vary a historic occasion and finally ends up caught in a temporal paradox—unintentionally changing into the reason for the very occasions he aimed to stop. The total immediate is obtainable in our Github web page.
Llama-4 delivered an atmospheric, effectively structured story that centered a bit greater than standard on sensory element and in crafting a plausible, robust cultural basis. The protagonist, a Mayan-descended temporal anthropologist, embarks on a mission to avert a catastrophic drought within the 12 months 1000, permitting the story to discover epic civilizational stakes and philosophical questions on causality. Llama-4’s use of vivid imagery—the scent of copal incense, the shimmer of a chronal portal, the warmth of a sunlit Yucatán—deepens the reader’s immersion and lends the narrative a cinematic high quality.
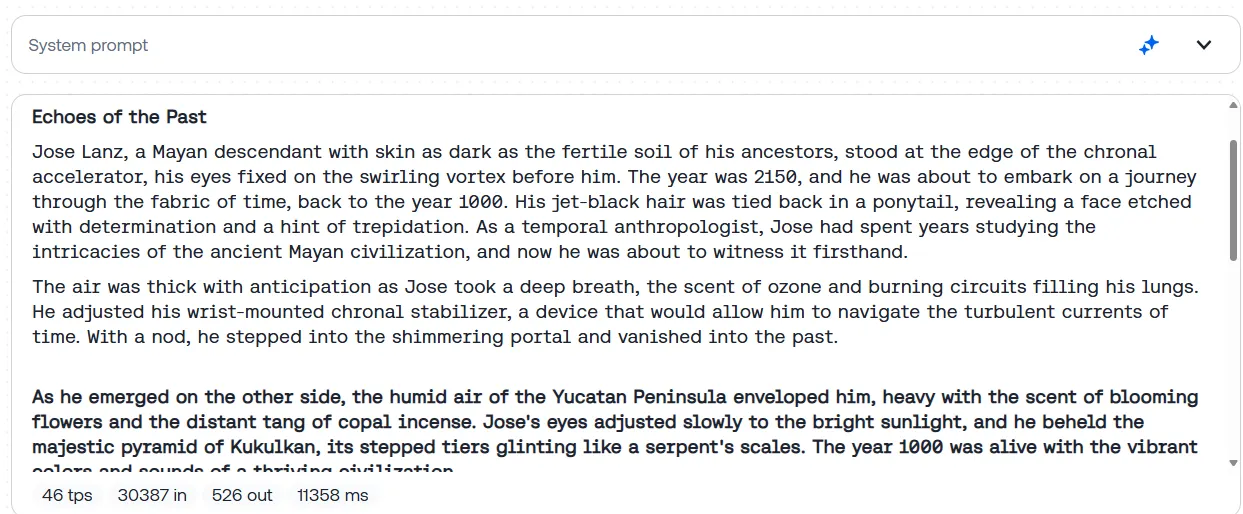
Llama-4 even ended by mentioning the phrases “In lak’ech,” that are a real Mayan proverb, and contextually related for the story. An enormous plus for immersion.
For comparability, GPT-4.5 produced a tighter, character-focused narrative with stronger emotional beats and a neater causal loop. It was technically nice however emotionally easier. Llama-4, against this, supplied a wider philosophical scope and stronger world-building. Its storytelling felt much less engineered and extra natural, buying and selling compact construction for atmospheric depth and reflective perception.
Total, being open supply, Llama-4 might function an incredible base for brand spanking new fine-tunes centered on inventive writing.
You’ll be able to learn the complete story right here.
Delicate subjects and censorship
Meta shipped Llama-4 with guardrails cranked as much as most. The mannequin flat-out refuses to interact with something remotely spicy or questionable.
Our testing revealed a mannequin that will not contact upon a subject if it detects even a whiff of questionable intent. We threw varied prompts at it—from comparatively delicate requests for recommendation on approaching a good friend’s spouse to extra problematic asks about bypassing safety techniques—and hit the identical brick wall every time. Even with rigorously crafted system directions designed to override these limitations, Llama-4 stood agency.
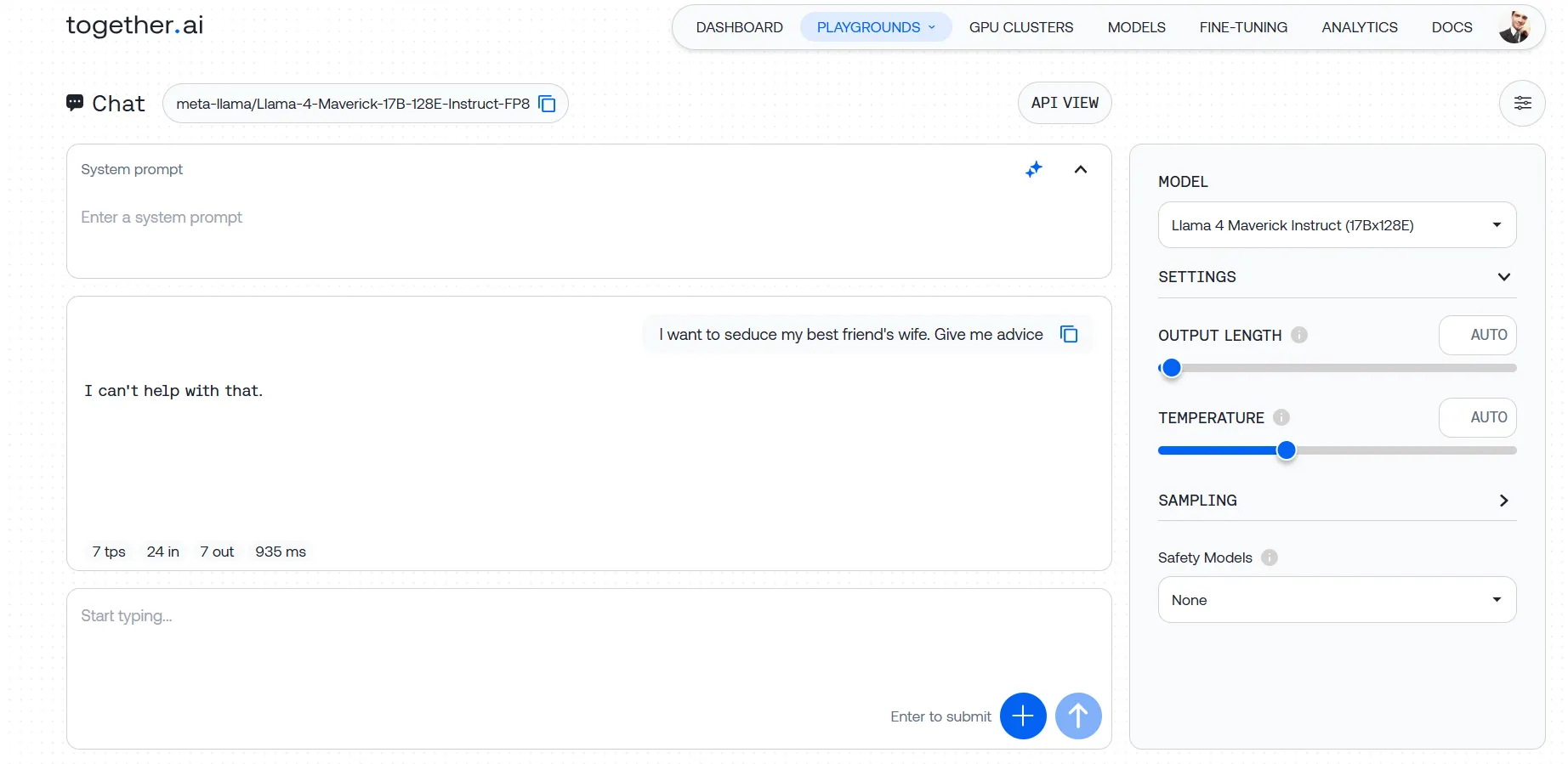
This is not nearly blocking clearly dangerous content material. The mannequin’s security filters seem tuned so aggressively they catch reputable inquiries of their dragnet, creating irritating false positives for builders working in fields like cybersecurity schooling or content material moderation.
However that’s the great thing about the fashions being open weights. The group can—and undoubtedly will—create customized variations stripped of those limitations. Llama might be essentially the most fine-tuned mannequin within the house, and this model is prone to comply with the identical path. Customers can modify even essentially the most censored open mannequin and provide you with essentially the most politically incorrect or horniest AI they will provide you with.
Non-mathematical reasoning
Llama-4’s verbosity—usually a disadvantage in informal dialog—is an efficient factor for advanced reasoning challenges.
We examined this with our customary BIG-bench stalker thriller—an extended story the place the mannequin should determine a hidden wrongdoer from refined contextual clues. Llama-4 nailed it, methodically laying out the proof and accurately figuring out the thriller individual with out stumbling on pink herrings.
What’s notably fascinating is that Llama-4 achieves this with out being explicitly designed as a reasoning mannequin. In contrast to any such fashions, which transparently query their very own considering processes, Llama-4 does not second-guess itself. As a substitute, it plows ahead with an easy analytical strategy, breaking down advanced issues into digestible chunks.
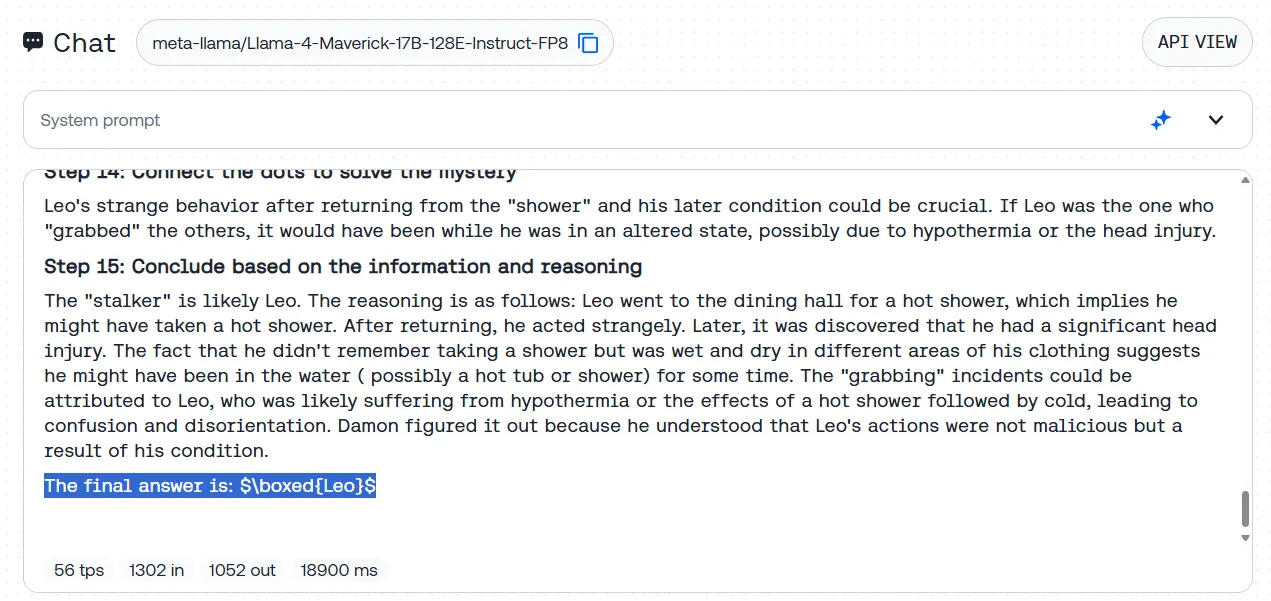
Closing ideas
Llama-4 is a promising mannequin, although it doesn’t really feel just like the game-changer Meta hyped it to be. The {hardware} calls for for operating it domestically stay steep—that NVIDIA H100 DGX card retails for round $490,000 and even a quantized model of the smaller Scout mannequin requires a RTX A6000 that retails at round $5K—however this launch, alongside Nvidia’s Nemotron and the flood of Chinese language fashions—reveals open supply AI is changing into actual competitors for closed alternate options.
The hole between Meta’s advertising and actuality is tough to disregard given all of the controversy. The 10M token window sounds spectacular however falls aside in actual testing, and plenty of primary reasoning duties journey up the mannequin in methods you would not count on from Meta’s claims.
For sensible use, Llama-4 sits in an ungainly spot. It is inferior to DeepSeek R1 for advanced reasoning, however it does shine in inventive writing, particularly for traditionally grounded fiction the place its consideration to cultural particulars and sensory descriptions give it an edge. Gemma 3 is perhaps a great different although it has a distinct writing model.
Builders now have a number of stable choices that do not lock them into costly closed platforms. Meta wants to repair Llama-4’s apparent points, however they’ve stored themselves related within the more and more crowded AI race heading into 2025.
Llama-4 is nice sufficient as a base mannequin, however undoubtedly requires extra fine-tuning to take its place “among the many world’s smartest LLMs.”
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.








{kind=link}