DeepSeek V4 may drop inside weeks, concentrating on elite-level coding efficiency.
Insiders declare it may beat Claude and ChatGPT on long-context code duties.
Builders are already hyped forward of a possible disruption.
DeepSeek is reportedly planning to drop its V4 mannequin round mid-February, and if inside assessments are any indication, Silicon Valley’s AI giants must be nervous.
The Hangzhou-based AI startup may very well be concentrating on a launch round February 17—Lunar New 12 months, naturally—with a mannequin particularly engineered for coding duties, in accordance with The Info. Folks with direct information of the venture declare V4 outperforms each Anthropic’s Claude and OpenAI’s GPT collection in inside benchmarks, notably when dealing with extraordinarily lengthy code prompts.
In fact, no benchmark or details about the mannequin has been publicly shared, so it’s inconceivable to immediately confirm such claims. DeepSeek hasn’t confirmed the rumors both.
Nonetheless, the developer group is not ready for official phrase. Reddit’s r/DeepSeek and r/LocalLLaMA are already heating up, customers are stockpiling API credit, and fans on X have been fast to share their predictions that V4 may cement DeepSeek’s place because the scrappy underdog that refuses to play by Silicon Valley’s billion-dollar guidelines.
Anthropic blocked Claude subs in third-party apps like OpenCode, and reportedly lower off xAI and OpenAI entry.
Claude and Claude Code are nice, however not 10x higher but. This can solely push different labs to maneuver sooner on their coding fashions/brokers.
DeepSeek V4 is rumored to drop…
— Yuchen Jin (@Yuchenj_UW) January 9, 2026
This would not be DeepSeek’s first disruption. When the corporate launched its R1 reasoning mannequin in January 2025, it triggered a $1 trillion sell-off in international markets.
The explanation? DeepSeek’s R1 matched OpenAI’s o1 mannequin on math and reasoning benchmarks regardless of reportedly costing simply $6 million to develop—roughly 68 occasions cheaper than what opponents had been spending. Its V3 mannequin later hit 90.2% on the MATH-500 benchmark, blowing previous Claude’s 78.3% and the current replace “V3.2 Speciale” improved its efficiency much more.
Picture: DeepSeek
V4’s coding focus can be a strategic pivot. Whereas R1 emphasised pure reasoning—logic, math, formal proofs—V4 is a hybrid mannequin (reasoning and non-reasoning duties) that targets the enterprise developer market the place high-accuracy code technology interprets on to income.
To say dominance, V4 would want to beat Claude Opus 4.5, which at present holds the SWE-bench Verified document at 80.9%. But when DeepSeek’s previous launches are any information, then this is probably not inconceivable to realize even with all of the constraints a Chinese language AI lab would face.
The not-so-secret sauce
Assuming the rumors are true, how can this small lab obtain such a feat?
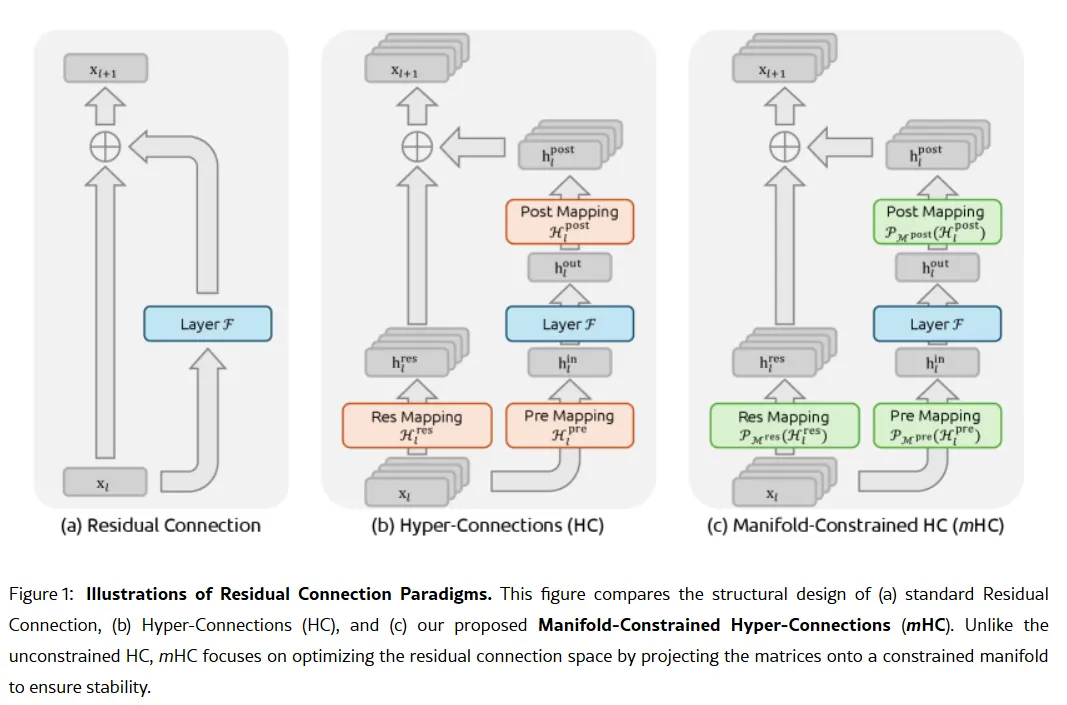
The corporate’s secret weapon may very well be contained in its January 1 analysis paper: Manifold-Constrained Hyper-Connections, or mHC. Co-authored by founder Liang Wenfeng, the brand new coaching technique addresses a basic downside in scaling giant language fashions—tips on how to increase a mannequin’s capability with out it turning into unstable or exploding throughout coaching.
Conventional AI architectures drive all info by way of a single slender pathway. mHC widens that pathway into a number of streams that may change info with out inflicting coaching collapse.
Picture: DeepSeek
Wei Solar, principal analyst for AI at Counterpoint Analysis, referred to as mHC a “hanging breakthrough” in feedback to Enterprise Insider. The method, she stated, reveals DeepSeek can “bypass compute bottlenecks and unlock leaps in intelligence,” even with restricted entry to superior chips because of U.S. export restrictions.
Lian Jye Su, chief analyst at Omdia, famous that DeepSeek’s willingness to publish its strategies indicators a “newfound confidence within the Chinese language AI business.” The corporate’s open-source method has made it a darling amongst builders who see it as embodying what OpenAI was once, earlier than it pivoted to closed fashions and billion-dollar fundraising rounds.
]]>
Not everyone seems to be satisfied. Some builders on Reddit complain that DeepSeek’s reasoning fashions waste compute on easy duties, whereas critics argue the corporate’s benchmarks do not mirror real-world messiness. One Medium submit titled “DeepSeek Sucks—And I am Completed Pretending It Would not” went viral in April 2025, accusing the fashions of manufacturing “boilerplate nonsense with bugs” and “hallucinated libraries.”
DeepSeek additionally carries baggage. Privateness considerations have plagued the corporate, with some governments banning DeepSeek’s native app. The corporate’s ties to China and questions on censorship in its fashions add geopolitical friction to technical debates.
Nonetheless, the momentum is plain. Deepseek has been broadly adopted in Asia, and if V4 delivers on its coding guarantees, then enterprise adoption within the West may comply with.
Picture: Microsoft
There’s additionally the timing. In line with Reuters, DeepSeek had initially deliberate to launch its R2 mannequin in Might 2025, however prolonged the runway after founder Liang grew to become dissatisfied with its efficiency. Now, with V4 reportedly concentrating on February and R2 probably following in August, the corporate is transferring at a tempo that means urgency—or confidence. Perhaps each.
Typically Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.








{kind=link}