
Prior to now weeks, researchers from Google and Sakana unveiled two cutting-edge neural community designs that would upend the AI trade.
These applied sciences goal to problem the dominance of transformers—a sort of neural community that connects inputs and outputs based mostly on context—the know-how that has outlined AI for the previous six years.
The brand new approaches are Google’s “Titans,” and “Transformers Squared,” which was designed by Sakana, a Tokyo AI startup recognized for utilizing nature as its mannequin for tech options. Certainly, each Google and Sakana tackled the transformer downside by finding out the human mind. Their transformers principally make the most of totally different levels of reminiscence and activate totally different skilled modules independently, as an alternative of participating the entire mannequin directly for each downside.
The online consequence makes AI techniques smarter, quicker, and extra versatile than ever earlier than with out making them essentially larger or costlier to run.
For context, transformer structure, the know-how which gave ChatGPT the ‘T’ in its identify, is designed for sequence-to-sequence duties resembling language modeling, translation, and picture processing. Transformers depend on “consideration mechanisms,” or instruments to grasp how vital an idea is relying on a context, to mannequin dependencies between enter tokens, enabling them to course of information in parallel relatively than sequentially like so-called recurrent neural networks—the dominant know-how in AI earlier than transformers appeared. This know-how gave fashions context understanding and marked a earlier than and after second in AI improvement.
Nonetheless, regardless of their exceptional success, transformers confronted vital challenges in scalability and flexibility. For fashions to be extra versatile and versatile, in addition they should be extra highly effective. So as soon as they’re educated, they can’t be improved except builders give you a brand new mannequin or customers depend on third-party instruments. That’s why at this time, in AI, “larger is healthier” is a normal rule.
However this will likely change quickly, because of Google and Sakana.
Titans: A brand new reminiscence structure for dumb AI
Google Analysis’s Titans structure takes a distinct strategy to enhancing AI adaptability. As an alternative of modifying how fashions course of info, Titans focuses on altering how they retailer and entry it. The structure introduces a neural long-term reminiscence module that learns to memorize at check time, much like how human reminiscence works.
Presently, fashions learn your complete immediate and output, predict a token, learn every thing once more, predict the subsequent token, and so forth till they give you the reply. They’ve an unimaginable short-term reminiscence, however they suck at long-term reminiscence. Ask them to recollect issues exterior their context window, or very particular info in a bunch of noise, and they’re going to in all probability fail.
Titans, then again, combines three forms of reminiscence techniques: short-term reminiscence (much like conventional transformers), long-term reminiscence (for storing historic context), and protracted reminiscence (for task-specific information). This multi-tiered strategy permits the mannequin to deal with sequences over 2 million tokens in size, far past what present transformers can course of effectively.
In keeping with the analysis paper, Titans reveals vital enhancements in numerous duties, together with language modeling, commonsense reasoning, and genomics. The structure has confirmed significantly efficient at “needle-in-haystack” duties, the place it must find particular info inside very lengthy contexts.
The system mimics how the human mind prompts particular areas for various duties and dynamically reconfigures its networks based mostly on altering calls for.
In different phrases, much like how totally different neurons in your mind are specialised for distinct features and are activated based mostly on the duty you are performing, Titans emulate this concept by incorporating interconnected reminiscence techniques. These techniques (short-term, long-term, and protracted reminiscences) work collectively to dynamically retailer, retrieve, and course of info based mostly on the duty at hand.
Transformer Squared: Self-adapting AI is right here
Simply two weeks after Google’s paper, a crew of researchers from Sakana AI and the Institute of Science Tokyo launched Transformer Squared, a framework that permits AI fashions to switch their habits in real-time based mostly on the duty at hand. The system works by selectively adjusting solely the singular parts of their weight matrices throughout inference, making it extra environment friendly than conventional fine-tuning strategies.
Transformer Squared “employs a two-pass mechanism: first, a dispatch system identifies the duty properties, after which task-specific ‘skilled’ vectors, educated utilizing reinforcement studying, are dynamically blended to acquire focused habits for the incoming immediate,” in keeping with the analysis paper.
It sacrifices inference time (it thinks extra) for specialization (understanding which experience to use).
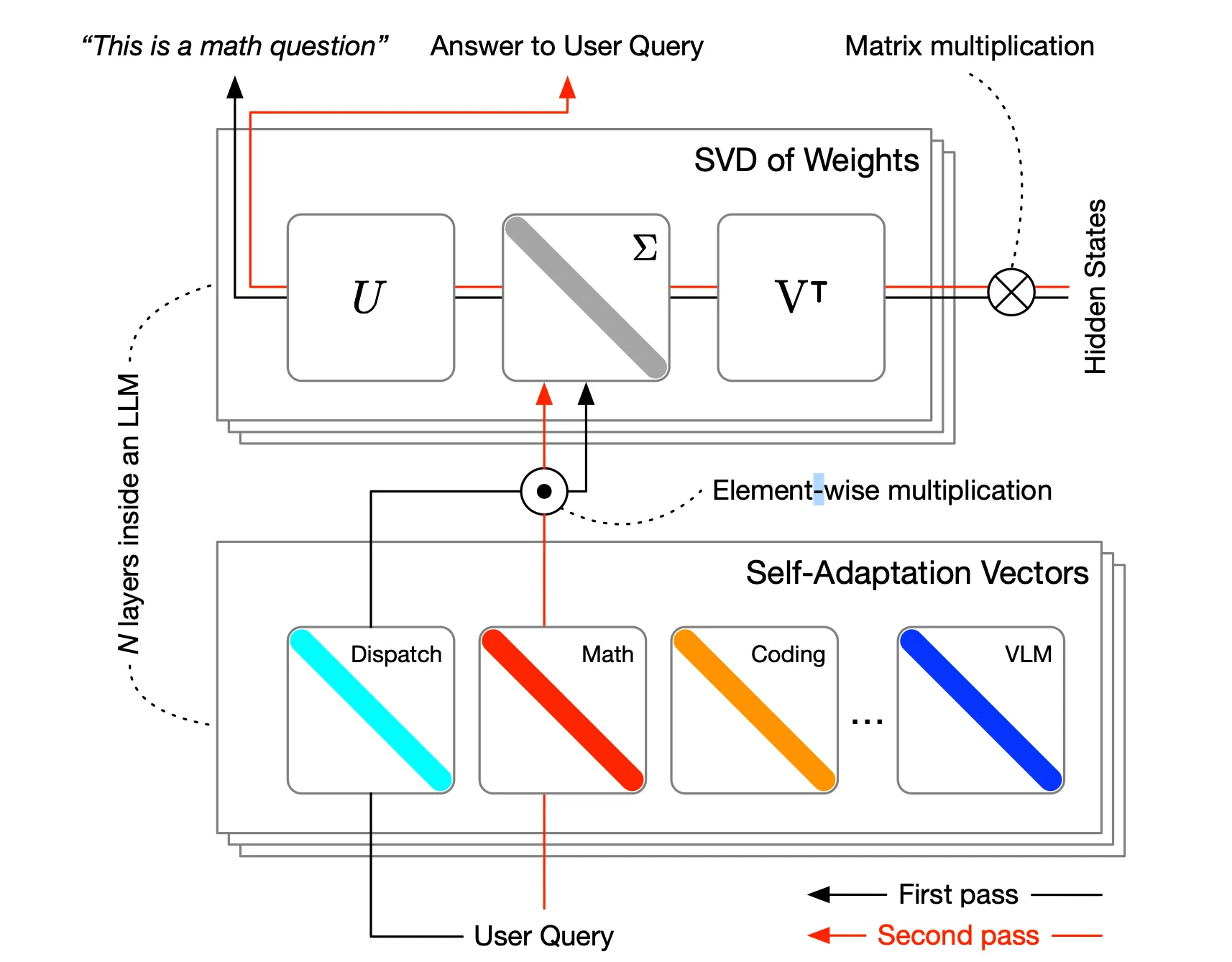
What makes Transformer Squared significantly revolutionary is its capability to adapt with out requiring intensive retraining. The system makes use of what the researchers name Singular Worth Nice-tuning (SVF), which focuses on modifying solely the important parts wanted for a selected activity. This strategy considerably reduces computational calls for whereas sustaining or enhancing efficiency in comparison with present strategies.
In testing, Sakana’s Transformer demonstrated exceptional versatility throughout totally different duties and mannequin architectures. The framework confirmed specific promise in dealing with out-of-distribution functions, suggesting it may assist AI techniques grow to be extra versatile and attentive to novel conditions.
Right here’s our try at an analogy. Your mind kinds new neural connections when studying a brand new ability with out having to rewire every thing. Once you study to play piano, for example, your mind would not have to rewrite all its information—it adapts particular neural circuits for that activity whereas sustaining different capabilities. Sakana’s thought was that builders don’t have to retrain the mannequin’s complete community to adapt to new duties.
As an alternative, the mannequin selectively adjusts particular parts (by means of Singular Worth Nice-tuning) to grow to be extra environment friendly at specific duties whereas sustaining its normal capabilities.
General, the period of AI corporations bragging over the sheer measurement of their fashions could quickly be a relic of the previous. If this new technology of neural networks features traction, then future fashions gained’t have to depend on huge scales to realize better versatility and efficiency.
At present, transformers dominate the panorama, typically supplemented by exterior instruments like Retrieval-Augmented Era (RAG) or LoRAs to boost their capabilities. However within the fast-moving AI trade, it solely takes one breakthrough implementation to set the stage for a seismic shift—and as soon as that occurs, the remainder of the sphere is certain to observe.
Edited by Andrew Hayward
Usually Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.








{kind=link}